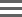Creating Sample Input Sheet Templates
Compatibility—NGS v5.16 and earlier
New in NGS 5.4—Input and output container UDF tokens
Before creating a sample input sheet template, ensure that you understand the sections of the template - as described in Sample Input Sheet Template Sections
The sample input sheet template is a comma-delimited CSV file. Its format must follow a few basic rules:
| • | Metadata entries must each appear on a new line and be the only entry on that line. Metadata entries must not appear inside tags. |
| • | Opening and closing tags must appear exactly as they are outlined below, on a new line and as the only entry on that line. |
| • | Each opened tag must be closed, otherwise it is skipped by the script. |
| • | The order of tags must be preserved: <HEADER_BLOCK>, <HEADER>, <DATA>, <FOOTER> |
| • | Any sections (opening tag + closing tag combination) can be omitted from the template file. |
| • | Entries that are separated by commas in the template will be delimited by the metadata-specified separator (default: COMMA) in the sample input sheet. |
| • | White space is allowed in the template. However, if there is a blank line inside a tag, it will also be present in the sample input sheet produced. |
| • | If an entry in the template is enclosed in double quotes it will be imported as a single entry and written to the sample input sheet as such, even if it has commas inside. |
| • | To include double-quotes (or single-quotes) in the sample input sheet, use theescape character: Example: \" or \' |
| • | To include an escape character in the sample input sheet, use two escape characters inside double-quotes. For example if you want to see \\Share\Folder\Filename.txt use "\\\\Share\\Folder\\Filename.txt" as the token. |
Example 1: Metadata, Sample In/Sample Out Process Type
Example 2: Sample In/ResultFile Out Process Type

Example 3: Sample In/Shared ResultFile Out Process Type

All of the tokens below must appear in the template in the following form: ${TOKEN}.
Example: ${PROCESS.LIMSID}
If your process contains ResultFile inputs or outputs, please refer to the Metadata section, specifically INCLUDE.INPUT.RESULTFILES and INCLUDE.OUTPUT.RESULTFILES.
|
Input Tokens |
Output Tokens |
|
INPUT.LIMSID |
OUTPUT.LIMSID |
|
INPUT.NAME |
OUTPUT.NAME |
|
INPUT.CONTAINER.NAME |
OUTPUT.CONTAINER.NAME |
|
INPUT.CONTAINER.LIMSID |
OUTPUT.CONTAINER.LIMSID |
|
INPUT.CONTAINER.TYPE |
OUTPUT.CONTAINER.TYPE |
|
INPUT.CONTAINER.ROW |
OUTPUT.CONTAINER.ROW |
|
INPUT.CONTAINER.COLUMN |
OUTPUT.CONTAINER.COLUMN |
|
INPUT.CONTAINER.PLACEMENT |
OUTPUT.CONTAINER.PLACEMENT |
|
INPUT.CONTAINER.UDF.name |
OUTPUT.CONTAINER.UDF.name |
|
INPUT.UDF.<UDF NAME> |
OUTPUT.UDF. <UDF NAME> |
|
INPUT.REAGENT.NAME |
OUTPUT.REAGENT.NAME |
|
INPUT.REAGENT.CATEGORY |
OUTPUT.REAGENT.CATEGORY |
|
INPUT.REAGENT.SEQUENCE |
OUTPUT.REAGENT.SEQUENCE |
|
INPUT.POOL.NAME |
|
|
INPUT.POOL.PLACEMENT |
|
|
INPUT.POOL.UDF. <UDF NAME> |
|
|
Process Tokens |
Submitted Sample Tokens |
|
PROCESS.LIMSID |
SAMPLE.LIMSID |
|
PROCESS.NAME |
SAMPLE.NAME |
|
PROCESS.TECHNICIAN |
SAMPLE.PROJECT.CONTACT |
|
PROCESS.UDF.<UDF NAME> |
SAMPLE.UDF. <UDF NAME> |
|
|
SAMPLE.PROJECT.NAME |
|
|
SAMPLE.PROJECT.LIMSID |
|
|
SAMPLE.UDT. <UDT NAME> . <UDF NAME> |
|
Misc Tokens |
Description |
|
INDEX |
Row number of the data row, index starting from 1 |
|
DATE |
Current date (i.e., when the script is being run) |
|
SAMPLE.PROJECT.NAME.ALL |
Prints all unique project names in a line, separated by LIST.SEPARATOR |
|
SAMPLE.PROJECT.CONTACT.ALL |
Prints all unique project contact names in a line (first name followed by last name) separated by LIST.SEPARATOR |
Each metadata entry must be on a separate line. These are not data tokens, so they do not need to be enclosed in tags.
When using OUTPUT.FILE.NAME, you may wish to give the file a name that does not begin with the LIMSID of the placeholder it will be attached to in the LIMS. To still attach this file, the quickAttach and destLIMSID parameters may be used in the EPP configuration for the sample input sheet file generation.
|
Name of Metadata Entry |
Description |
|
SCRIPT.VERSION |
Version of the compatible DriverFileGenerator.jar file, please include this entry into your templates. Example: SCRIPT.VERSION,1.0.2 |
|
OUTPUT.TARGET.DIR |
Provide this token to specify the directory in which to write the sample input sheet file . If the directory or its parent directories do not exist, they will be created. Example: OUTPUT.TARGET.DIR,/Users/LabTech/DriverFiles/ |
|
OUTPUT.FILE.NAME |
Provide this token to rename the sample input sheet with the specified name. Example: OUTPUT.FILE.NAME,NewDriverFileName.csv |
|
OUTPUT.SEPARATOR |
The sample input sheet will be delimited with the specified separator. The default sample input sheet delimiter used is COMMA. Refer to the Special Characters section of this page to determine if the separator must be provided using a keyword. Example: OUTPUT.SEPARATOR,TAB |
|
LIST.SEPARATOR |
Tokens that return lists (e.g., SAMPLE.PROJECT.NAME.ALL) will be separated by the specified String. Example: LIST.SEPARATOR,"; " |
|
ILLEGAL.CHARACTERS |
Specify characters that must not appear in the file produced. Each illegal character will be replaced with its corresponding replacement specified by the replacements token. Refer to the Special Characters section of this page to determine if the illegal character must be specified using a keyword. Example: ILLEGAL.CHARACTERS,TAB,PERIOD,#,<,>,etc |
|
ILLEGAL.CHARACTER.REPLACEMENTS |
Provides the replacement policy for each illegal character. The number of replacements provided must match the number of specified illegal characters (If only one replacement character is specified, it will be used to replace all illegal characters); replacement will be performed in corresponding order. Example: ILLEGAL.CHARACTER.REPLACEMENTS, _,",",_,_ ,_,_ ILLEGAL.CHARACTER.REPLACEMENTS,_ |
|
SORT.BY. |
Specify tokens by which the data will be sorted alphanumerically within the sample input sheet file. More than one token can be provided e.g., to sort by container placement by row follow the usage example to the right, to sort by placement with multiple containers present provide the container name token as a sort option as well. For more information, see Sorting Logic. Example: SORT.BY.${INPUT.CONTAINER.ROW}${INPUT.CONTAINER.COLUMN} |
|
SORT.VERTICAL |
Sort data by container placement by column. SORT.BY.${INPUT.CONTAINER.ROW}${INPUT.CONTAINER.COLUMN} must be present in the template as well, otherwise SORT.VERTICAL will have no effect. For more information, see Sorting Logic. Example: SORT.VERTICAL |
|
PROCESS.POOLED.ARTIFACTS |
Include artifacts stored in pools into the sample input sheet generation as if they were regular input artifacts. Example: PROCESS.POOLED.ARTIFACTS |
|
INCLUDE.INPUT.RESULTFILES |
Includes input ResultFiles in the sample input sheet file. (By default these are excluded.) Example: INCLUDE.INPUT.RESULTFILES |
|
INCLUDE.OUTPUT.RESULTFILES |
Includes output ResultFiles in the sample input sheet file. (By default these are excluded.) Example: INCLUDE.OUTPUT.RESULTFILES |
|
EXCLUDE.INPUT.ANALYTES |
Excludes analyte (sample) inputs from the sample input sheet file. (By default these are included.) Example: EXCLUDE.INPUT.ANALYTES |
|
EXCLUDE.OUTPUT.ANALYTES |
Excludes analyte ( sample) outputs from the sample input sheet file. (By default these are included.) Example: EXCLUDE.OUTPUT.ANALYTE |
|
Keyword |
Character Represented |
|
COMMA |
, |
|
TAB |
tab |
|
PERIOD |
. |
|
BACKSLASH |
\ |
|
OPENING_BRACE |
{ |
|
CLOSING_BRACE |
} |
|
DOLLAR_SIGN |
$ |
|
SINGLE_QUOTE |
' |
|
DOUBLE_QUOTE |
" |
|
PIPE |
| |
|
OPENING_PARENTHESIS |
( |
|
CLOSING_PARENTHESIS |
) |
|
OPENING_BRACKET |
[ |
|
CLOSING_BRACKET |
] |
|
QUESTION_MARK |
? |
|
ASTERISK |
* |
|
PLUS_SIGN |
+ |
|
CARET |
^ |
Sorting in the file is done either alphanumerically or by vertical placement information. To sort vertically, include the token SORT.VERTICAL in the metadata section of the template file.
The following sorting metadata must also be included in the file:
SORT.BY.${OUTPUT.CONTAINER.ROW}${OUTPUT.CONTAINER.COLUMN}
At this point any SORT.BY tokens will be sorted using the vertical sorter instead of the alphanumeric sort.
An important thing to note about sorting is that it must be done using a combination of sort keys (provided to SORT.BY) that always produce a unique value in the file.
For example, sorting by just OUTPUT.CONTAINER.NAME would not work for samples in 96 well plates, but would work for samples placed in tubes.
To apply sorting to samples in 96 well plates you could narrow the sort key to a unique combination such as:
SORT.BY.${OUTPUT.CONTAINER.NAME}${OUTPUT.CONTAINER.ROW}${OUTPUT.CONTAINER.COLUMN}
Sorting behavior on non-unique combinations is not guaranteed to be predictable.