Select the Optimal Batch Size
The Clarity LIMS API has batch retrieve endpoints for samples, artifacts, containers, and files. This article talks generically about links for any of those four entities.
When using the batch endpoints, you want to process upwards of hundreds of links. Intuitively, you may think that a single API call with all the links would be the fastest way to retrieve the data. However, analysis of the API performance shows that as the number of links increases beyond a threshold, the time per object increases.
To retrieve the data in the most efficient way, it is best to do multiple POSTs containing the optimal sized batch. A batch call takes longer than a GET to the endpoint of the sample to retrieve the data for a single sample (or other entity). However, after more than one or two samples are needed, the batch endpoint is more efficient.
Before you follow the example, make sure that you are aware of what the optimal batch size is based on the following information:
| • | The optimal size depends on your specific server and the number of UDFs/custom fields or other data attached to the object being retrieved. |
| • | The optimal batch size can be different for artifacts, samples, files, and containers. For example, if the optimal size for samples is 500, 10 batches of 500 samples retrieve the data faster than one batch of 5000. |
You must also have a compatible version of API (v2 r21 or later).
Attached is a simple python script that will time how long batch retrieve takes for an array of batch sizes. The efficiency is measured by the duration of the call divided by the number of links posted.
The attached script has hard coded parameters to define the range and increments of batch sizes to test. Also, the number of replications for each size is adjustable. These parameters are found on line 110, and may not require any modification because they are already set to the following by default:
replications = 3 # how many times each batch will be measuredrepetitions = 1 # how many measurements will be taken for each batch sizeR = range( 100, 300 ) # range of the batch sizes to be measured (where min >= 1)q = 25 # batch size incremental increase
For example, the previous parameters test the following sizes: 100, 125, 150, 175, 200, 225, 250, 275.
The parameters that will must specific to the server are entered at the command line.
| • | -u—Username |
| • | -p—Password |
| • | -s—Hostname, including /api/v2 |
| • | -t—Entity (eg, artifact, sample, file, or container) |
An example of the full syntax to invoke the script is as follows.
python BatchOptimalSizeTest.py -p apipassword -u apiuser -s https://demo.basespacelims.com/api/v2 -t artifact
The script tracks how long each batch call takes to complete. The script outputs a .txt file with the raw numeric data and the batch size that returns the minimum value, and is the most efficient.
Analyzing results for: artifactBatch sizes:[25, 50, 75, 100, 125, 150, 175, 200, 225, 250, 275, 300, 325, 350, 375, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700, 725, 750, 775, 800, 825, 850, 875, 900, 925, 950, 975]Time (s) per entity:[0.061350816726684576, 0.04790449237823486, 0.040710381189982096, 0.03354618215560913, 0.033738230133056636, 0.03324082946777344, 0.03209760447910854, 0.03409448790550232, 0.03184072346157498, 0.031050360870361327, 0.029453758586536753, 0.03295832395553589, 0.03149744004469652, 0.03347888347080776, 0.033550281016031906, 0.030628018498420718, 0.03328620989182416, 0.03454347112443712, 0.035195479945132606, 0.0361147011756897, 0.03584921982174828, 0.0383262753053145, 0.037979933946029, 0.03772751696904501, 0.03774445213317871, 0.03933756652245155, 0.04524845660174335, 0.03916741977419172, 0.04273618560001768, 0.043037356503804525, 0.04183078679730815, 0.044450711250305176, 0.0478362009453051, 0.04694189671909108, 0.044135747201102124, 0.04349724955028958, 0.04686621408204775, 0.046690188458091336, 0.05018808247492863] Duration (s) of batch call: [1.5337704181671143, 2.395224618911743, 3.053278589248657, 3.354618215560913, 4.21727876663208, 4.986124420166016, 5.617080783843994, 6.8188975811004635, 7.1641627788543705, 7.762590217590332, 8.099783611297607, 9.887497186660767, 10.236668014526368, 11.717609214782716, 12.581355381011964, 12.251207399368287, 14.146639204025268, 15.544562005996704, 16.717852973937987, 18.057350587844848, 18.820840406417847, 21.079451417922975, 21.838462018966673, 22.636510181427003, 23.590282583236693, 25.569418239593507, 30.54270820617676, 27.417193841934203, 30.983734560012817, 32.278017377853395, 32.418859767913816, 35.56056900024414, 39.46486577987671, 39.90061221122742, 38.61877880096436, 39.14752459526062, 43.351248025894165, 44.35567903518677, 48.93338041305542]275 artifacts was the most efficient batch size
Viewing this data in a scatterplot format, you can see the range of optimal batch sizes for the artifacts/batch/retrieve endpoint is about 200 to 300 artifacts. This would be valid for artifacts only and each entity (eg, sample, file, or container) should be evaluated separately.
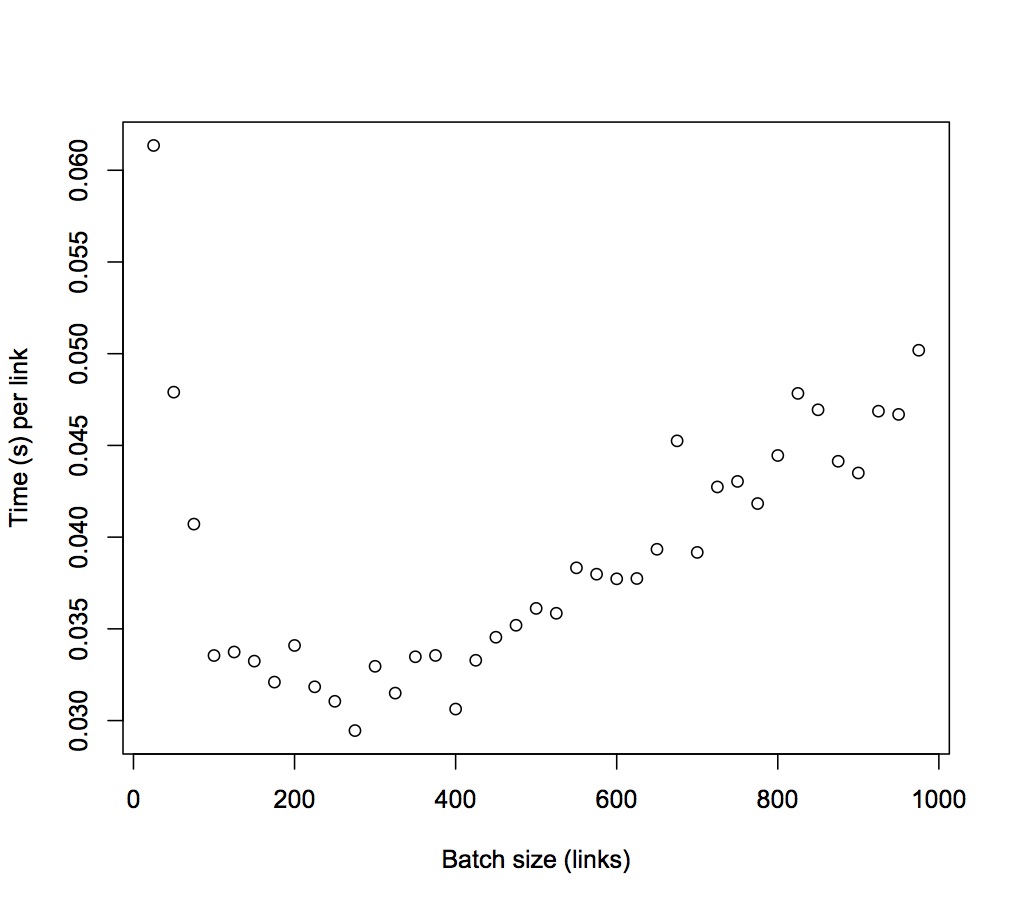
The shortest time per artifact is the most efficient batch size, as shown in the following example:
275 artifacts was the most efficient batch size
By default, the Clarity LIMS configuration of send and receive timeout is 60 seconds. Large batch calls will not complete if their duration is greater than the timeout configuration. This configuration is at /etc/httpd/conf/httpd.conf.