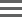Structure of REST Resources
The information recorded in BaseSpace Clarity LIMS is organized into resources within the REST API. Each resource refers to an XML schema associated with a namespace. Before working with the REST Web Service, understand how the information recorded in Clarity LIMS translates to the REST resources.
The following diagram highlights the major REST resources. Each resource is discussed further in the following sections.
| • | Samples are the objects that are entered into Clarity LIMS before processing begins. Every sample belongs to a single project and has a related analyte (sample) artifact. Every project must have an associated researcher. |
| • | When you add a sample to the system, it is classified as a submitted sample. This feature allows the original samples, and any related data, to remain separate and distinct, even as processing and aliquot creation occurs. Every sample or file created by running a step from the Clarity LIMS user interface can be traced back to a submitted sample. |
| • | In Clarity LIMS, processes (know as steps in the user interface) are run on analyte (derived sample) artifacts. Samples must always be in containers. |
| • | Clarity LIMS v4.x and earlier: In the Clarity LIMS Operations Interface processes are run on analyte (sample) or result file artifacts. Samples must always be in containers. |
| – | As of BaseSpace Clarity LIMS v5, the Operations Interface Java client used by administrators to configure processes, consumables, user-defined fields, and users have been deprecated. All configuration and administration tasks are now executed in the Clarity LIMS web interface. |
| – | To understand how API terminology maps to terminology used in the Clarity LIMS v5 interface, see Understanding API Terminology (LIMS v5 and later). |
Within the REST Web Service, the samples resource is key.
The samples resource represents submitted samples and contains information about those samples, including:
| • | The dates samples are entered and received. |
| • | Any user-defined data related to the samples. |
When a sample is added to Clarity LIMS, the system also creates an artifact (see Artifacts).
While the artifact associated with a submitted sample is only seen at the database or REST level, and is never exposed in the Clarity LIMS interface, the system uses this artifact when running protocol steps.
When running a step on a submitted sample, the artifact is used as an input to the step, not the submitted sample itself. All artifacts reside within the artifacts resource.
When a submitted sample is processed, the system generates output artifacts. Depending on the configuration of the process, many types of artifacts (including result files) can be generated. Any downstream sample created by running a process is considered an analyte artifact (referred to as a derived sample in the user interface).
Projects are used to group samples based on the originating lab (account) or study. Projects collect all records related to that sample in Clarity LIMS.
A project stores information about:
| • | The client (researcher) who owns it |
| • | Significant dates |
| • | The status of the project |
| • | Any user-defined information that the lab needs to collect |
After creating a project, you can add samples to it. Samples can then be added to workflows, and steps (processes) are run on those samples to reflect the analysis performed in the lab.
In the REST Web Service, a submitted sample can only belong to one project. You can use the projects resource to return projects.
Note the following details regarding projects:
| • | Every submitted sample must belong to a project. |
| • | Every project must be assigned to a researcher (an owner) that corresponds to a client in the system. |
| • | In the Clarity LIMS user interface, the term contact has been replaced with client. However, the API permission is still called contact. |
The researchers resource represents clients in the system.
When working with projects, each project must list a client as the owner of the project. This role generally represents the person who submitted the original samples.
The client does not need to have a user account.
In Clarity LIMS v5, the API still uses the term process. However, in the user interface, this term has been replaced with master step. Also, the Operations Interface has been deprecated.
| • | Clarity LIMS v4.2 and earlier—Created in the Clarity LIMS Operations Interface, process types model and track the work performed on the samples in the lab. In the Clarity LIMS web interface, these process types are then used as building blocks to create and configure steps in the Clarity LIMS web interface. These steps are known as processes in the API. |
| • | Clarity LIMS v5 and later—Created in the Clarity LIMS web interface, master steps model and track the work performed on the samples in the lab. These master steps are then used as building blocks to create and configure steps. These steps are known as processes in the API. |
Different interfaces may allow you to run steps/processes on different artifacts.
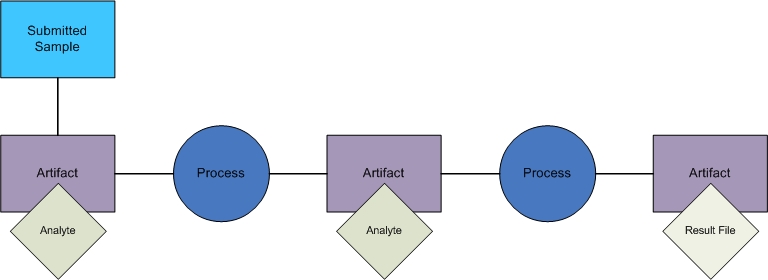
In the API view, a process takes in one or many analytes and/or result files and creates one or many analytes and/or result files.
When running a step in Clarity LIMS, lab scientists record information about the step, the instruments used, and the properties and characteristics of the samples.
Depending on the configuration of the process/master step on which it is based, the step can generate another sample analyte and/or placeholders to which result files can be attached for storage in the system.
With the REST Web Service, the processes resource is used to track these activities.
Note the following details regarding processes:
| • | Processes are used to represent work that occurs in the lab or in silico. |
| • | Processes take inputs and create outputs. With the REST processes resource, it is modeled using the input-output-map element. |
In addition to tracking historical work via the processes resource in the REST Web Service, use the service to POST new processes to the system.
POSTing a process to the REST Web Service creates the process itself, along with the outputs of the process. However, all the input and output containers must exist in the system already.
| • | For a simple example of the XML required to POST a process, see the processes (list) section of the REST resources space. |
| • | For basic details about POSTing processes, see Working with Processes/Steps in the Cookbook section. |
| • | For examples of process POSTing, see Pooling Samples with Reagent Labels and Demultiplexing in the Cookbook section. |
| • | To find out how to integrate automation with process POSTing to set quality control flags, see the Setting Quality Control Flags application example. |
Query the processes resource using input artifact LIMS IDs. This query allows you to find the processes that were run at each step in the workflow or on each artifact generated during processing.
All inputs and outputs of a process are artifacts and can be returned via the artifacts resource.
Note the following details about artifacts:
| • | An artifact is a derivative of a sample and is used as an input to a process. |
| • | An artifact may be a sample analyte or a result file. |
| • | The artifacts resource includes artifacts for the submitted sample and all process outputs, both file- and sample-based. |
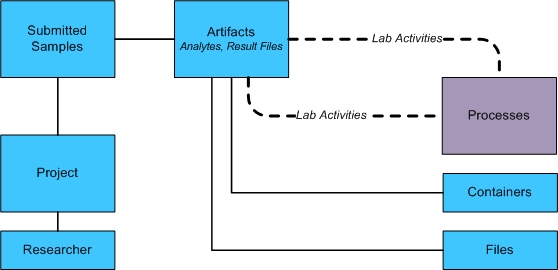
Artifacts are categorized by type, to distinguish between pure information results (file-based artifacts, such as result files) and the biological material created by processing the sample (analyte artifacts).
In Clarity LIMS, the term artifact is used to describe items needing to be processed. Think about artifacts as the intellectual property added by the lab.
For example, applying reagents to change the nature of a sample creates an artifact, as does generating and analyzing data files by running a sample on a NextGen or microarray instrument.
Anything created by a process in the system is an artifact. In the REST Web Service, there are several types of artifacts, but this article focuses on two:
| • | Computer-generated files called result files |
| • | Physical sample derivatives called analytes |
The high-level relationship between artifacts, analytes, and result files is shown in the following diagram.
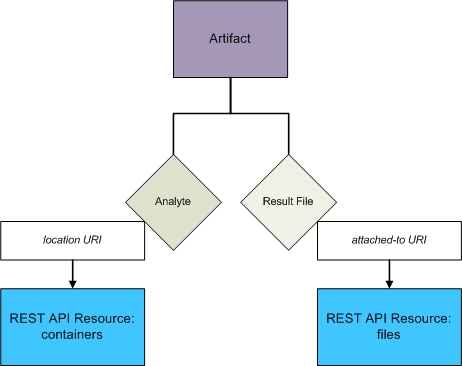
An artifact references data elements, which vary depending on the type of artifact you are working with. For example, a result file has an attached-to URI that links to a files resource, whereas an analyte has a location URI that links to the containers resource.
Artifacts are key to tracking lab process activities and also link to a submitted sample.
All artifacts include one or more sample URI data elements, which make it easy to trace any lab-generated product or result directly back to its original sample.
When working with artifacts in the REST API, their URIs often include a numeric state. The state is used to track historical QC, volume, and concentration values.
Unless you are interested in a historical state, it is best practice not to include state when using an artifact URI. When state is omitted, the API defaults to the most recent state.
When samples are processed in the lab, they are always placed into containers of some sort (tubes, 96-well plates, flow cells, etc.) and moved into new containers as processing occurs.
For many kinds of processing, the container placement is a critical piece of information. Further processing of the sample, and data files created by analyzing the sample, are often linked based on the placement of the sample in the container.
Containers are central to processing in the lab. In Clarity LIMS, therefore, the samples (analyte artifacts) must also always be placed into a container resource.
When working with the REST Web Service, analyte artifacts include a URI that links to the container housing the artifact. Use the containers resource to view all the containers registered in the system.
Details on finding contents of a container can be found in the About the Cookbook.
Note the following details about containers:
| • | Containers represent the tubes, plates, flow cells, and other vessels that can be populated with a sample. |
| • | All samples/analytes must reside in a container or they are not visible in Clarity LIMS client. |
All containers include a name and a LIMS ID.
| • | The name is a text element over which the scientific programmer has full control. |
| • | The LIMS ID is a unique identifier generated by the system in a fixed format. |
The name, LIMS ID, and any container-level User-Defined Fields (UDFs) provide various options for container labeling.
For assistance, the Illumina Consulting team can recommend various settings, such as uniqueness constraints, based on your requirements.
A lab produces various files: large scientific result data files, summary result files, image files, label files, equipment and robotic setup files, and software logs.
These files are stored in different locations and it can be challenging to manage the relationship between a file on a computer or hard disk and the sample, step, or project with which it is associated.
Clarity LIMS lets you store files related to a project or sample and files generated during a step in a workflow. These files can be imported in various locations within the client and are stored on the file server.
To model this feature within the REST Web Service, there are two resources:
| • | files resource |
| • | glsstorage resource |
Within the REST Web Service, files are represented by the files resource. This resource manages files and the resources or artifacts to which they are related, and stores information about:
| • | The sample, project, or process output with which the file is associated, referenced by the attached-to URI. |
| • | Where the file was imported from, and its original name, referenced by the original-location URI. |
| • | The location of the file, referenced by the content-location URI. It also specifies the transfer protocol that can be used to retrieve the file. The following transfer protocols are supported: |
| – | FTP |
| – | SFTP |
| – | HTTP |
Files Added using the LIMS Client
If using REST to view a file that was added through the Clarity LIMS client, the content-location URI references a location on the file server. This location is where the system stores all files that are imported through the Clarity LIMS client.
Files Added using REST
If you are using REST to import a file into the system, do one of the following:
Store the file on the file server:
| 1. | Use the glsstorage resource to create a unique storage location and file name on the file server. |
| 2. | After this step is complete, the system returns a location and file name using the content-location URI element. |
| 3. | Then do as follows. |
| • | Provide the URI to the files resource. |
| • | Put the file in the specified location. |
Store the file somewhere other than on the file server:
| • | Use the files resource and reference the name and location of your file with the content-location URI element. |
| • | This feature must be configured by Illumina. For more information, contact the Support team. |
Not the following key concepts:
| • | Files—The files resource defines the location of a file and its relationship with other REST resources, such as artifacts and projects. |
| • | Glsstorage—The glsstorage resource allocates space on the file server. |
| • | XML elements—Within the XML used by the files and glsstorage resources, the attached-to and content-location URIs are used to link disk files to file-based artifacts produced by a process or to link disk files to projects or samples. |
The following diagram outlines how the XML elements link files to system resources and artifacts:
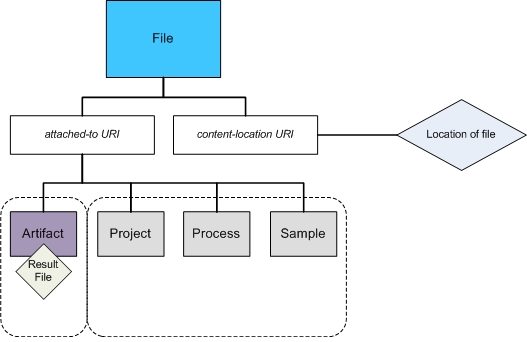
In the lab, one of the most important associations to make is between:
| • | A file that is the result of an instrument run. |
- and -
| • | The sample that was analyzed to produce that file. |
In Clarity LIMS, this association is represented by creating a process that takes a sample analyte and produces a result file.
When you run a process configured to create a result file, the process generates a placeholder for a file. To populate the placeholder, simply import the result file generated by the instrument into Clarity LIMS.
While working in the lab, lab scientists can upload result files that are used or produced while samples are processed. However, it may sometimes be more appropriate to automate this work. In these cases, you can use the REST files and the glsstorageresource.
Depending on the file storage needs and how the files are generated, there are two ways to do this process.
| • | Import a file and store it on the file server. |
| • | Import a file and store it on a different server. |
To import a result file and store it on the file server:
| 1. | POST conforming XML to the glsstorage resource. |
| 2. | This action returns XML that includes a name and storage location for the file. |
| 3. | Place the file into the specified location using the file name provided in the XML. |
| 4. | POST the returned XML to the files resource, which links the file on disk to the result file placeholder. |
To import a result file and store it on a different server:
| 1. | Make sure that the file exists in the desired location. |
| 2. | POST conforming XML to the files resource, referencing the name and location of your file with the content-location element. The file path must contain the transfer protocol supported by the server. For example: |
sftp://192.168.13.247/home/glsftp/Process/2010/10/SCH-RAA-101013-87-1/ADM53A1PS3-40-1.dat
It is not necessary to POST to the glsstorage resource.
If you have files that were not generated during the analysis of a sample, you can also attach reference information to projects and samples.
For example, suppose you receive an email when a sample is submitted to the lab, you may want to store that information in Clarity LIMS. In this case, when you POST XML to the files resource, the XML links the file to the desired submitted sample, instead of to a result file placeholder.
Clarity LIMS v5.x and later:
In Clarity LIMS, the file is attached to the Sample Details section of the Sample Management screen.
| 1. | On the Projects and Samples screen, select the project containing the sample for which you have posted a result file. |
| a. | Scroll down to the Samples and Workflow Assignment section of the screen and select the appropriate sample. |
| b. | Select Modify 1 Sample. |
| 2. | On the Sample Management screen, scroll to the bottom of the Sample Details section to find the attached file. |
Before Clarity LIMS v5:
In the Clarity LIMS web interface, the file is attached to the Sample Details section of the Sample Management screen.
For details on accessing the file, see the previous content on Clarity LIMS v5.x and later.
In the Clarity LIMS Operations Interface, the file is attached to the Files tabbed page of the applicable submitted sample.
| 1. | In the Clarity LIMS Explorer, select Opened Projects. |
| 2. | In the Opened Projects list, double-click the project containing the sample for which you have posted a result file. |
| 3. | On the project details page, select the Samples tab. |
| 4. | At the bottom of the tab in the Containers pane, double-click the appropriate sample. |
| 5. | On the sample details page, select the Files tab to find the attached file. |
Before POSTing to the files resource, make sure that the file exists in the location referenced by the content-location element. If the file does not exist in this location, the POST fails.
The REST Web Service separates the resources needed for files and file storage.
This action allows for greater control and the flexibility to apply various tracking and storage strategies. The content-location element can be used to define the file location without having to move the file. This ability is key in next-generation sequencing, which requires the management of large files, such as assemblies.
The content-location element needs to reference the file location in a storage system using a specific file transfer protocol. Currently only FTP, SFTP, and HTTP protocols are supported.
This mechanism makes file management flexible, but it maintains access to the file from REST with a single link. However, this feature must be configured by Illumina. For more information, contact the Support team.
Note the following key concepts about UDFs and UDTs:
| • | UDFs and UDTs are configured to collect information that is important to the lab. |
| • | With the REST Web Service, include UDF and UDT values in the XML representation of any individual resource that has a UDF or UDT defined. |
| • | Not all artifacts have both UDFs and UDTs. |
In Clarity LIMS v5 and later:
| • | The API still uses the term UDF. However, in the user interface, this term has been replaced with custom field. |
| • | UDTs are not supported. |
You can configure the system to collect user-defined information. Consider the following examples:
| • | You can create UDFs to add options and fields to the user interface when working with samples, containers, artifacts, processes/protocol steps, and projects. |
| • | You can also create User-Defined Types (UDTs), which are organized subsets of related UDFs. As you add and process samples, you can add information to these options and fields. |
In the following example, UDFs are added to submitted samples, processes, and sample analytes (derived samples).
| • | For the submitted sample named Goo, there are UDFs named Type, Color, and Source. |
| • | For the Prepare Goo process/step, there are UDFs named Reagent Lot ID, Temperature, and Cycle Time. |
| • | The output of the Prepare Goo process/step is an analyte named Prepared Goo, which contains UDFs named Quality and Category. |
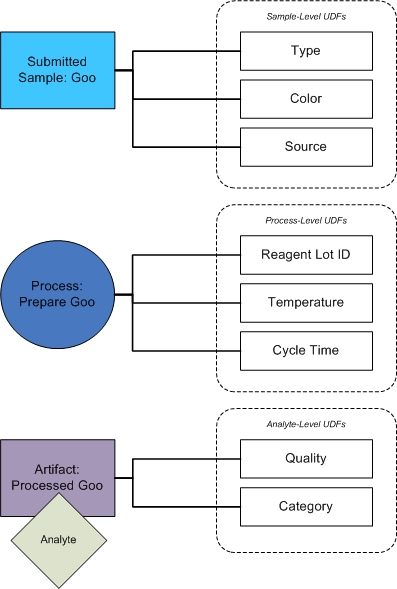
Any downstream sample created by running a process is considered an analyte artifact. In the Clarity LIMS interface, analyte artifacts are referred to as derived samples. For more information, see Samples, Artifacts, and Processes.
To record information for these UDFs:
| 1. | Add Goo to the system and populate the sample-level UDFs. |
| 2. | In Clarity LIMS, run the Prepare Goo step and complete the following actions: |
| • | Populate the Step Details fields (the process-level UDFs). |
| • | Populate the Sample Details table (the analyte-level UDFs). |
Using the REST Web Service to Collect UDF Information
You can also use the REST Web Service to collect user-defined information for samples, containers, artifacts, and processes.
After you have configured UDFs, the XML of the appropriate resource expands with data elements for the field values. For example, the Prepared sample of goo artifact would have the following XML:
<art:artifact uri="http://yourIPaddress:8080/api/v1/artifacts/ADM54A1PR4?state=321" limsid="ADM54A1PR4">
<name>Prepared sample of goo</name>
<type>Analyte</type>
<output-type>Analyte</output-type>
<parent-process uri="http://yourIPaddress:8080/api/v1/processes/PRE-MMS-100903-24-63" limsid="PRE-MMS-100903-24-63"/>
<qc-flag>UNKNOWN</qc-flag>
<location>
<container uri="http://yourIPaddress:8080/api/v1/containers/27-82" limsid="27-82"/>
<value>1:1</value>
</location>
<working-flag>true</working-flag>
<sample uri="http://yourIPaddress:8080/api/v1/samples/ADM54A1" limsid="ADM54A1"/>
<udf:field type="String" name="Quality">Excellent</udf:field>
<udf:field type="Numeric" name="Category">1</udf:field>
</art:artifact>
Configuring UDFs/Custom Fields
UDFs/custom fields are useful for collecting data at various stages of your workflow. In next-generation sequencing, it is important to record information, such as who submitted a sample, the tested concentration of a library, the reagents that were used during library prep.
As illustrated in the previous Goo example, collect this information by adding UDFs/custom fields for the samples, artifacts, and processes resources:
| • | A submitted sample UDF/custom field named Type |
| • | An artifact-level UDF/derived sample custom field named Validated Concentration |
| • | A process-level UDF/master step field named Reagent Name |
Artifact UDFs/custom fields are flexible.
| • | You can configure different sets of UDFs/custom fields for the analyte artifact type and the result file artifact type. |
| • | You can configure different sets of UDFs/custom fields based on the process type. |
This flexibility means that:
| • | Process type/master step A can display fields m and n on a result file and fields q and r on an analyte. |
| • | Process type/master step B can display fields m and o on a result file and fields q and s on its output analyte. |
|
Process Type/Master Step |
Result File Field Exposed |
Analyte Field Exposed |
|
A |
m, n |
q, r |
|
B |
m, o |
q, s |
Control how users access artifact-level UDFs/custom fields by configuring the type of artifact or process type/master step to which they apply.
Not every detail tracked and recorded needs a UDF. To optimize lab efficiency, it is recommended that you define an essential UDF set.
Increasing the complexity of information collected and managed does not necessarily improve operations or scientific quality. It may be more effective to store files, because the complete details are then available and secure within the attached file.